힙 정렬이란 무엇입니까?.
힙 정렬최대 힙 트리 또는 최소 힙 트리를 구성하여 정렬하는 방식입니다.
내림차순 정렬~을 위한 최대 힙형태
오름차순 정렬~을 위한 최소 더미형태
힙 정렬은 1964년 JWJ Williams에 의해 발명되었으며 같은 해 RW Floyd는 내부 정렬을 수행할 수 있는 개선된 버전을 발표했으며 이 방법은 트리 정렬 알고리즘을 사용하는 방법입니다.
힙 정렬 시뮬레이션.
다음 그림은 힙 정렬을 시뮬레이트합니다.
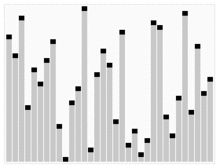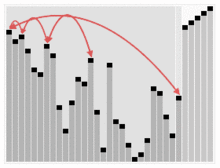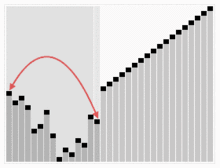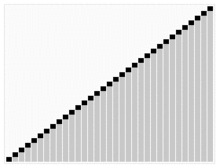
또한 숫자로 된 힙 정렬을 보고 싶다면 아래 웹사이트를 방문하는 것이 좋다.
힙 정렬 프로세스.
힙 정렬 과정을 알기 위해서는 힙 데이터 구조를 미리 공부하는 것이 중요하다.
힙의 데이터 구조를 모르는 경우 (데이터 구조) 힙 포스트 한번 봅시다.
이제 힙 데이터 구조를 알고 있다고 가정하고 프로세스를 설명하겠습니다.
- n 노드에 대해 완전한 이진 트리를 구성합니다. 이때 루트 노드, 부모 노드, 왼쪽 자식 노드, 오른쪽 자식 노드가 순서대로 조립된다.
- 최대 힙 구성 최대 힙은 상위 노드가 하위 노드보다 큰 트리입니다.
종단노드를 자식노드로 가지는 부모노드에서 형성되며 밑에서부터 루트까지 순차적으로 만들 수 있다. - 가장 큰 숫자(루트에 위치)를 끝에 있는 노드와 교환합니다.
- 2와 3 반복
이제 위의 알고리즘을 시뮬레이션으로 검증해 보자.
(6, 5, 3, 1, 8, 7, 2, 4) 배열을 오름차순으로 정렬하는 문제가 있다고 가정합니다.
위에서 설명한 것처럼 정렬은 오름차순입니다. 최대 힙정렬을 수행합니다.

- 먼저 이진 검색 트리를 만듭니다. 최대 힙구현
- 그 후 최대 힙의 최대 루트 노드가 배열의 마지막 요소로 설정되고 그 위치는 트리의 마지막 노드와 교체됩니다.
- 모든 위치가 결정될 때까지 이 프로세스를 반복하여 최대 힙을 만들고 루트 노드를 배열의 마지막 요소로 만듭니다.
힙 정렬 시간 복잡도.
힙 구현 포스팅에서 보았듯이 최대 힙을 생성하는 과정(heapify)의 시간복잡도가 높다. 오전.
이 heapify 과정은 n개의 요소가 모두 정렬될 때까지 반복되므로 최종 heapsort의 시간복잡도는 같다. 된다
힙 정렬 구현 코드.
// c++ 로 구현한 힙 정렬
#include <iostream>
using namespace std;
// i 노드가 가장 큰 노드인 힙트리를 만들기 위한 함수
// 힙 사이즈는 n
void heapify(int arr(), int n, int i)
{
int largest = i; // 루트를 가장 큰 노드로 초기 설정
int l = 2 * i + 1; // left
int r = 2 * i + 2; // right
// 왼쪽 자식 노드가 가장 큰 노드보다 클 때
if (l < n && arr(l) > arr(largest))
largest = l;
// 오른쪽 자식 노드가 가장 큰 노드보다 클때
if (r < n && arr(r) > arr(largest))
largest = r;
// 만약, 가장 큰 노드가 루트가 아니면 스왑
if (largest != i) {
swap(arr(i), arr(largest));
// 재귀적으로 서브트리를 힙화 한다.
heapify(arr, n, largest);
}
}
// 힙 정렬 함수
void heapSort(int arr(), int n)
{
// 힙을 구성 (배열 재 정렬)
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
// 하나씩 힙에서 원소를 추출
for (int i = n - 1; i > 0; i--) {
// 루트노드를 끝 노드로 이동
swap(arr(0), arr(i));
// 줄어든 힙에서 최대 힙 구성
heapify(arr, i, 0);
}
}
// n 크기의 배열을 출력하는 코드
void printArray(int arr(), int n) {
for (int i = 0; i < n; ++i)
cout << arr(i) << " ";
cout << "\n";
}
int main() {
int arr() = { 12, 11, 13, 5, 6, 7 };
int n = sizeof(arr) / sizeof(arr(0));
heapSort(arr, n);
cout << "정렬된 배열은 : \n";
printArray(arr, n);
}
힙 정렬 기능 요약.
- 정렬에 추가 메모리가 필요하지 않습니다. (현장에서 분류 가능)
- 최고, 평균 및 최악의 heapify 프로세스가 필요하므로 nlogn이 보장됩니다.
- 데이터의 순서를 보장하지 않는 불안정한 데이터 정렬입니다.
- 힙 정렬과 퀵 정렬을 비교하면 같은 nlogn이지만 컴퓨터의 하드웨어 구조상 퀵 정렬이 실제로 더 빠르다고 합니다. 그 이유는 퀵 정렬은 요소가 인접한 메모리 영역에 추가되는 배열을 사용하기 때문에 일반적으로 캐시 친화적이기 때문입니다.
힙 정렬의 요소는 종종 더 분산되어 있으므로 캐시 선호도가 좋지 않은 문제가 있습니다.
이는 일반적으로 힙 정렬이 많은 포인터 산술을 사용하기 때문에 관련된 오버헤드를 무시할 수 없기 때문입니다.
가능한 인터뷰 질문.
- 힙 정렬 과정을 설명해주세요.
- 힙 정렬의 시간복잡도는? 왜 이러한 시간적 복잡성이 있습니까?
- 힙 정렬과 퀵 정렬 중 어느 것이 더 빠릅니까?